2. 了解数据集¶
人工智能或者数据分析是基于数据的科学,我们需要对我们的数据进行初步收集整理后才能 进行下一步的实质性工作。 在searborn或者sklearn模块中,有一些内置数据集 可以让我们方便的使用,一般被当做课堂案例。
2.1. Seaborn鸢尾花(Iris)数据集¶
Iris也称鸢尾花卉数据集,是常用的分类实验数据集。
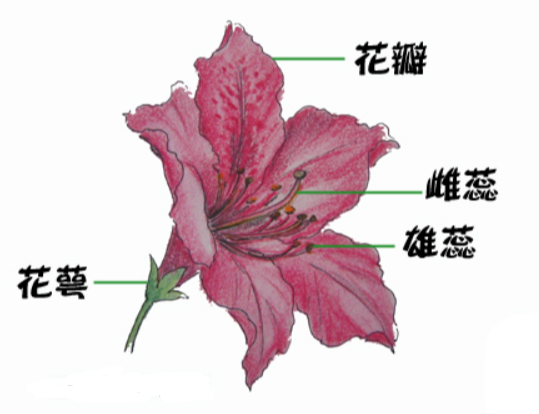
- R.A. Fisher于1936年收集整理的
- 包含3种植物种类,分别是:
- 山鸢尾(setosa)
- 变色鸢尾(versicolor)
- 维吉尼亚鸢尾(virginica)
- 每类50个样本,共150个样本
- 包含4个特征变量,1个类别变量
- 4个特征为:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
- 以及1个类别变量
# Iris问题 seaborn数据集
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
上面所列出的是Iris数据集的一个简单描述。
2.2. 几个常用数据相关概念¶
- 特征(Feature): 数据的表头通常被称为特征, 可以理解为数据的标签,例如sepal_length
- 样本(Sample): 标准每一行为一个样本,用来表示一个具体的数据
- 一个特征矩阵就是维度为[n_samples, n_features]的二维矩阵
- 特征矩阵:
这是一个为二位表格形式的数据,类似Excel表示的形式,我们通常把这类二维数组或者矩阵形式 表示的数据称为特征矩阵, 通常被简记为X(大写X)。通常可以用pandas.DataFrame或者SciPy的稀疏矩阵 - 目标数组:
目标数组一遍标记为y,一般是和样本总数长度一致的一维数组,例如上面数据的species列
2.3. Scikit-learn数据集表示方法¶
sklearn的数据集相比较seaborn复杂一些,毕竟面对的工作方向不同。
2.3.1. SKlearn数据集的获取¶
Sklearn把数据集分成了三大类,常见scikit-learn的数据集获取有三个方法:
- 自带的小数据集:
- 数据包含在datasets里
- 一般使用load_XXX加载
- 包含波士顿房价,鸢尾花,乳腺癌等。
- 自带的大数据集
- 需要从互联网上下载
- 使用fetch_XXX进行下载
- 需要指定data_home表示数据集下载的目录,默认 ~/scikit_learn_data/
- 要修改默认目录,可以修改环境变量SCIKIT_LEARN_DATA
- 自动生成数据
- 还可以自己生成实验数据
- 通过函数datasets.make_xxx
2.3.2. datasets.base.Bunch类¶
Sklearn数据集是加工后的数据,不是简单一堆数字,对数据集sklearn有自己独特的描述方法, load_XX和 fetch_XX 函数返回的数据类型是 datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。
Bunch主要包含以下属性:
- data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名
- target_names:标签名
其中对数据集的其他操作主要包括数据集目录的获取,删除等:
- datasets.get_data_home: 数据集目录
- datasets.clear_data_home(data_home=None): 删除所有下载数据
# 得到数据集的默认存放地址
from sklearn.datasets import *
rst = get_data_home()
print(rst)
C:\Users\augsnano\scikit_learn_data
下面我们看下sklearn中Iris数据集的具体信息:
# Iris问题
#装载数据集
from sklearn.datasets import load_iris
# 载入实验数据
iris_dataset = load_iris()
# 了解实验数据
#花瓣花萼数据
print("Features Names: {} \n".format(iris_dataset.feature_names))
print(" \nThe first 5 datas: \n {}".format(iris_dataset.data[:5]))
#结果数据
print(" \nTargetName:\n {}".format(iris_dataset.target_names))
print(" \nThe first 5 targets:\n {}".format(iris_dataset.target[::10]))
#数据即的键值
print(" \nAll Keys: \n {}".format(iris_dataset.keys()))
Features Names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
The first 5 datas:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
TargetName:
['setosa' 'versicolor' 'virginica']
The first 5 targets:
[0 0 0 0 0 1 1 1 1 1 2 2 2 2 2]
All Keys:
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])