{% raw %}
7. 1.1. 广义线性模型¶
校验者: @专业吹牛逼的小明 @Gladiator @Loopy @qinhanmin2014 翻译者: @瓜牛 @年纪大了反应慢了 @Hazekiah @BWM-蜜蜂
本章主要讲述一些用于回归的方法,其中目标值 y 是输入变量 x 的线性组合。 数学概念表示为:如果 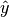 是预测值,那么有:
是预测值,那么有:
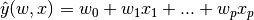
在整个模块中,我们定义向量 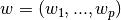 作为
作为 coef_ ,定义 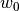 作为
作为 intercept_ 。
如果需要使用广义线性模型进行分类,请参阅 logistic 回归 。
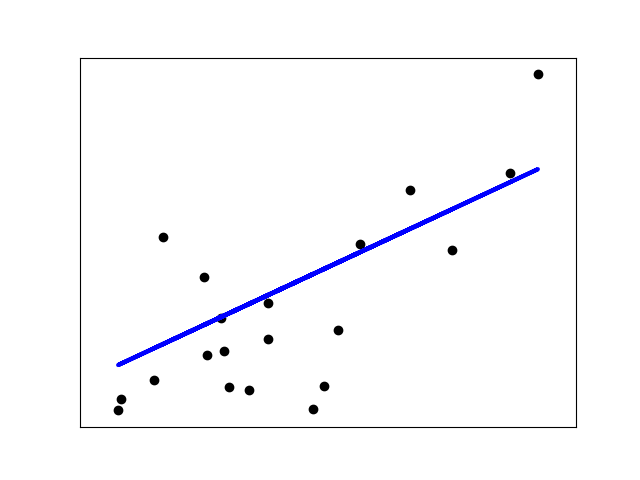
7.1. 1.1.1. 普通最小二乘法¶
LinearRegression 拟合一个带有系数 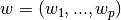 的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:
的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:
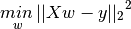
LinearRegression 会调用 fit 方法来拟合数组 X, y,并且将线性模型的系数 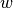 存储在其成员变量
存储在其成员变量 coef_ 中:
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])